A Carrier Bag Filled with Glitches, Errors, and Artificial Stupidity
Adriaan Odendaal & Karla Zavala (Internet Teapot)
Carrier Bag
Intelligence
Langage :
en
carrier-bag categories-classifications datasets economy content-moderation extractivism text labour labels classism meme communities tech-solutionism recommendations pop-culture robots facial-recognition
We are internet teapot, a small Rotterdam-based research & design studio created by Karla Zavala Barreda and Adriaan Odendaal. The “internet teapot” is our sigil of sorts, based on an obscure internet error you might not have known existed. Just like you often find a webpage returning a frustrating 404 “Page Not Found” error, you might also stumble upon the absurd (yet equally legitimate) 418 “I’m a Teapot” error. It’s an actual, albeit nonsensical, HTTP error that the Internet Engineering Task Force IETF (charged with the serious task of setting internet standards and protocols) created in 1998 as a joke in case anyone would “attempt to brew coffee with a teapot” on the internet.
For us, this internet protocol easter egg says something about all digital technologies: that below the functionalist surface running smoothly, there is always traces of the culture, contradictions, humour, failures, foibles, absurdities, and personalities of those who create them. We often forget this fact when confronted with the hype of Artificial Intelligence (AI) as a technology that can supersede human failings and shortcomings through the autonomous action of incomprehensibly complex calculations.
Yet instead of possessing a supernatural superior intelligence, more often than not these systems are prone to absurd failures that betray their true nature: that far from being infallible, they are error-prone computer systems created by equally error-prone humans. As Hito Steyerl suggests, it’s more appropriate to call these systems “Artificial Stupidity” than “Artificial Intelligence”. Being more conscious and critical of the innate stupidity in these systems can help us pierce through the dazzling hype of AI and possibly prevent the often disastrous mistakes these technologies make when blindly trusted and left unchecked.

In the spirit of the 418 “I’m a teapot” error, we have collected a series of absurd AI glitches and errors in our post-digital carrier bag and emptied them out on this webpage for you to explore. We invite you to rummage through these examples of “Artificial Stupidity”, presented through artworks, podcasts, memes, and more. After all, it is often the errors and glitches that best break the precarious illusions we have about technology. As Torben Sangild writes:
»A tool (e.g., a hammer) is transparent in the sense that we think of it as purely functional. When it breaks, however, we become aware of its construction and design.«
Feel free to scroll down through the errors below, or hop around by clicking on the error code you’d like to:
Error 101
Error 413
Error 065
Error 506
Error 432
Error 706
Error 988
Error 101: World Dispatch - Mechanical Turk
AI technologies are often presented as possessing an acute advanced intelligence above and beyond any other mechanical system in need of human operation. Its intelligence is seen as manifested in its ability to make completely autonomous decisions, deductions or deliberations. However, as one of our favourite podcast episodes from the online magazine The Outline’s World Dispatch series shows: the complex tasks said to be deftly handled by an “intelligent” AI system often ends up being the result of manual operation by or intervention from humans.
The hosts of The Outline World Dispatch 11/28/2017: Mechanical Turk & Phish details the case of the tech-startup Expensify. This company promised to help users do quick automated invoicing using their advanced image recognition AI service, yet Expensify actually outsourced the work of the most advanced AI services to underpaid human workers on Amazon’s Mechanical Turk digital gig-work platform.
Much like the medieval chess-playing automaton after which the digital gig-work platform is named, what this episode shows is that the “intelligence” often ascribed to perceptibly smart technologies hides the active human labour that goes into making it seem like AI is at work. This does not merely go for outright fraud cases or examples of so-called “pseudo-AI”. Even exemplary AI technologies like Google’s voice assistant needs input and review from “language experts” to process voice commands from different languages. A selection of telling headlines illustrates how human labour is often employed to do the work behind AI:
Underpaid Workers Are Being Forced to Train Biased AI on Mechanical Turk
The Humans Hiding Behind the Chatbots
Facebook's Virtual Assistant 'M' Is Super Smart. It's Also Probably a Human
AI: Ghost Workers Demand to be Seen and Heard
AI systems often need active course correction, learning system guidance, edge-case handling, manual moderation, data labelling, and much more from humans (see also: Error 506). It’s always important to question how much of the “intelligence” of an AI system is automated, and how much of it comes down to the wide-ranging hidden human labour compensating for the innate machine stupidity of the system.
Error 413: Algorithms of Late Capitalism Zines
Discussions about harmful social consequences resulting from AI errors often occur in very circumscribed situations: a university classroom, a journal article, a policy framework, a white paper, a conference. There is a need to create more critical public discourses and spaces for discussion about AI technology and the ways it impacts our own daily lives. Therefore, the next object in our post-digital carrier bag of errors is a series of community co-created zines edited by yours truly: The Algorithms of Late Capitalism zines.

ISSUE 1: Things We Taught the Machines To Do
ISSUE 2: Embodied Surveillance
ISSUE 3: Minorities Report - Speculative Subversions
ISSUE 4: [D/R]econstructing AI: Dreams of Visionary Fiction
ISSUE 5: Shifting the Power
Algorithms of Late Capitalism (ALC) started as a blog and Instagram page where we curate tech news, memes, and internet found-images that reflect how global market forces and hegemonic power structures often shape digital technologies such as AI, resulting in all sorts of absurd and often disastrous socio-technical problems. For example:

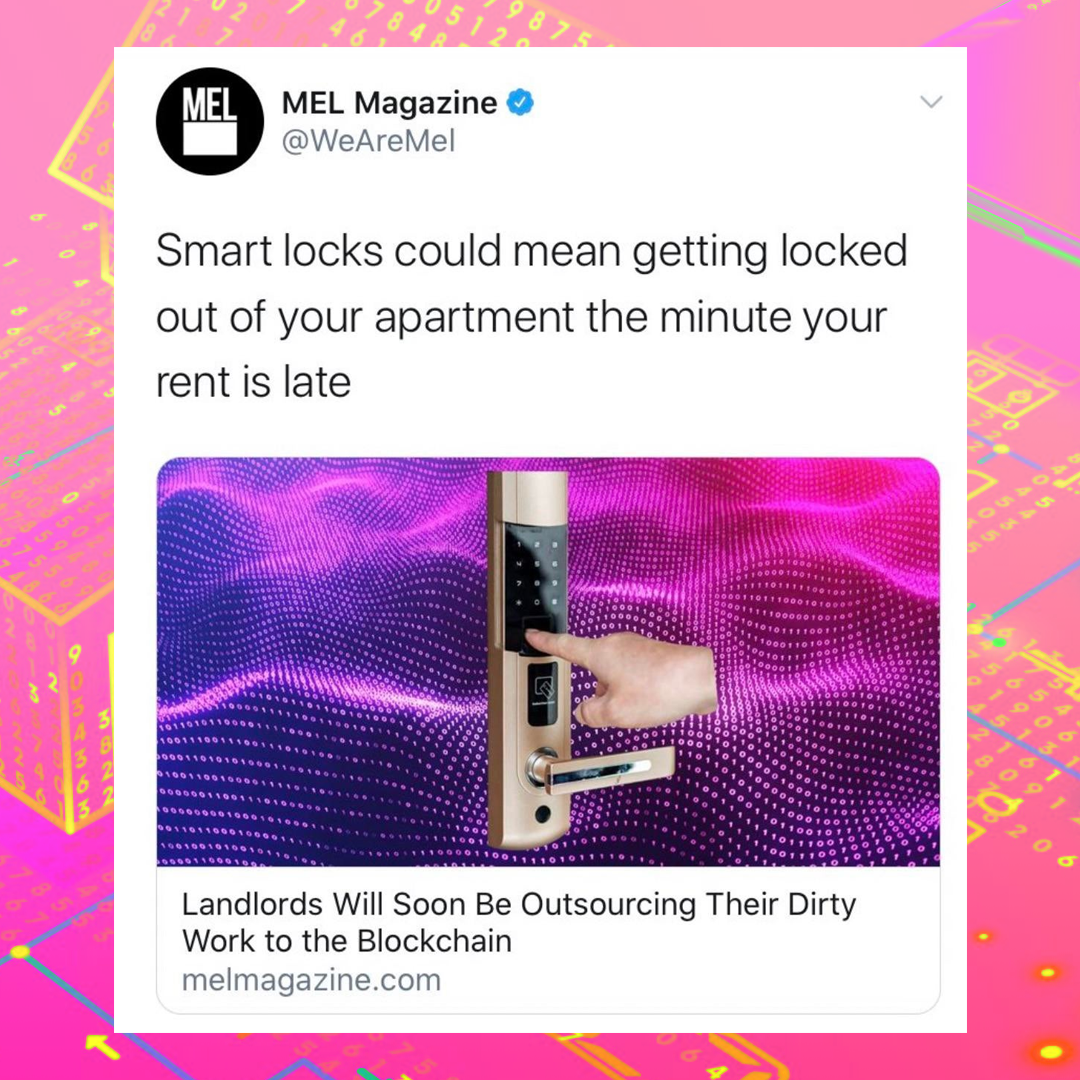

Eventually, ALC turned into a series of zine co-creation workshops frequently held online throughout the last two years during which participants collaborate to create one issue of the ALC zine. Remix culture is at the core of these workshops. On each page of each zine, you will find different ideas communicated through collages, screenshots, and drawings that often poignantly reflect on the absurdities of digital technologies. Through creative remixing, participants and readers are encouraged to decode and recode the ALC blog’s content, often containing tech news and trends. The result is satirical and comical explorations of absurd errors arising from the deployment of digital technologies such as AI. Thus, rather than promoting the same hype around AI technology as Silicon Valley marketers, these zines offer a space for people to create and explore counter-discourses.
Zines, as opposed to white papers or journal articles, can free up the discussion about AI technology by opening them to more informal contexts. The communal and creative nature of zine-making can also help turn this intimidatingly technical and complex topic into something more engaging and accessible. After all, these self-published small-circulation magazines are born out of a counterculture tradition meant to challenge the status quo of official and top-down discourse. And while many might have assumed that the rise of blogs and micro-blogging would result in the disappearance of zine culture, DYI zines have not lost their relevance. In fact, zines have re-emerged as a powerful form of tech criticism. One project that inspired our work is Tiny Tech Zines.
We include this collection of zines in our carrier bag to celebrate open public discussions about AI, while also pointing out how prevalent and problematic the errors created by “smart” technologies such as AI are (there are still a lot more zines to be added to this series!). When perusing an ALC issue, always remember: behind the humour, there are very critical discussions that we should be having.
P.S. The ALC zine is under creative commons (meaning you can print it and distribute it as well)! 😉
Download the print-ready versions here.
Error 065: Stupid Shit No One Needs & Terrible Ideas Hackathon
The tech industry has a severe case of techno-solutionism when it comes to AI. It is obsessed with applying AI as a seemingly groundbreaking answer to any problem they can think of. Evgeny Morozov describes such solutionism as “an intellectual pathology that recognizes problems as problems based on just one criterion: whether they are ‘solvable’ with a nice and clean technological solution at our disposal”. Tech-solutionism is often the cause of much artificial stupidity.

Few projects so absurdly satirize techo-solutionism as the Stupid Shit No One Needs & Terrible Ideas Hackathon. This one-day event was organized by Sam Lavigne & Amelia Winger-Bearskin and brought participants together to conceptualize and create tech projects that had no real value and addressed no real problems. Prompts for participants included: “Monetizing the Glass Ceiling”; “Privatising reading a book before you go to bed”; “Extracting Value from Barely Audible Sighs at a Dinner Party”; and other ludicrous ideas. Exemplary tech products created during the hackathon included an iPhone app that tells you whether you are holding your phone and a Chrome extension that blocks all website content that isn’t an ad.
The techno-solutionist pathology that underlies the hackathon model of innovation also pervades the rise of AI services and products. We’ve seen everything from AI-powered toothbrushes to toilets to clickbait-journalism. However, the indiscriminate application of AI to all domains of human life can also have adverse social consequences when not thoroughly thought-through and merely seen as a quick catch-all solution or new market to corner. For example: the deployment of AI technologies to immigration processes has led to human rights abuses; while the use of AI to screen inmates for parole has led to the automated perpetuation ofinstitutionalized racial discrimination.
When there is scant consideration of whether it is appropriate to apply AI technology to a certain domain of life, we often end up with artificial stupidity at its worst. Perhaps AI-powered criminal justice systems or immigration screening (amongst many other examples) should also be seen as terrible ideas and stupid shit that nobody needs.
Error 506: Survival of The Best Fit
AI often employs machine learning models that automatically update its own parameters as it learns to make increasingly accurate predictions or decisions based on large sets of training data. But the term “learn” is perhaps somewhat misleading as these systems merely embark on a process of reinforcing refinement of statistical patterns found through iterative data processing. Often times this leads to the automatic exacerbation of problematic patterns that the algorithm might have established based on the data it was trained on (see also: Error 988).

Due to our love of critical play as a powerful playful medium to explore complex topics, we wanted to include the browser-based game Survival of the Best Fit in our collection of errors. In this game, you play as a business owner of a fledgling startup. At first, you hire new employees by selecting them yourself. But as your business grows, you start employing an AI human resources management service to automate the hiring process. As the Best Fit software engineer in the game informs you: “We built a hiring algorithm using machine learning. Basically, we will teach a computer to hire like you, but way faster!” However, you soon discover, the AI is rejecting great candidates based on seemingly arbitrary or correlative (but inconsequential) data-driven decisions such as whether they are blue or orange.
Survival of the Best Fit quickly conveys the problem with real-world hiring biases perpetuated by AI using machine learning processes. In an actual audit of a CV screening system, investigators found that the two factors the system thought were most indicative of job performance were “being named Jared ” and “having played lacrosse in high school”. A machine learning system might just as easily come to the conclusion that certain ethnic groups are better or worse candidates and use that as an invisible metric in a company’s hiring processes. In fact, Amazon’s machine-learning specialists uncovered that their recruiting software had a strong bias against hiring women. It penalized resumes that included the word “women’s” (as in “women’s chess club captain”). While Amazon updated the system to make it neutral to these particular terms, this was no guarantee that the system would not devise other ways of sorting candidates that could prove discriminatory. Why? One of the reasons is that machine-learning systems are black boxes that sometimes make inscrutable decisions based on absurd patterns it identifies in training data. Machine learning systems do not learn from their mistakes like humans might – instead, they compound and automate their mistakes until humans hopefully intervene.
Error 432: Other Orders
Intelligence in “Artificial Intelligence” seems to imply some kind of perceptiveness and agency - the ability to make decisions on its own and come to unique conclusions distinct from those of its human creators. However, this view ignores the fact that these systems are often computational manifestations of the worldviews of those that created it.
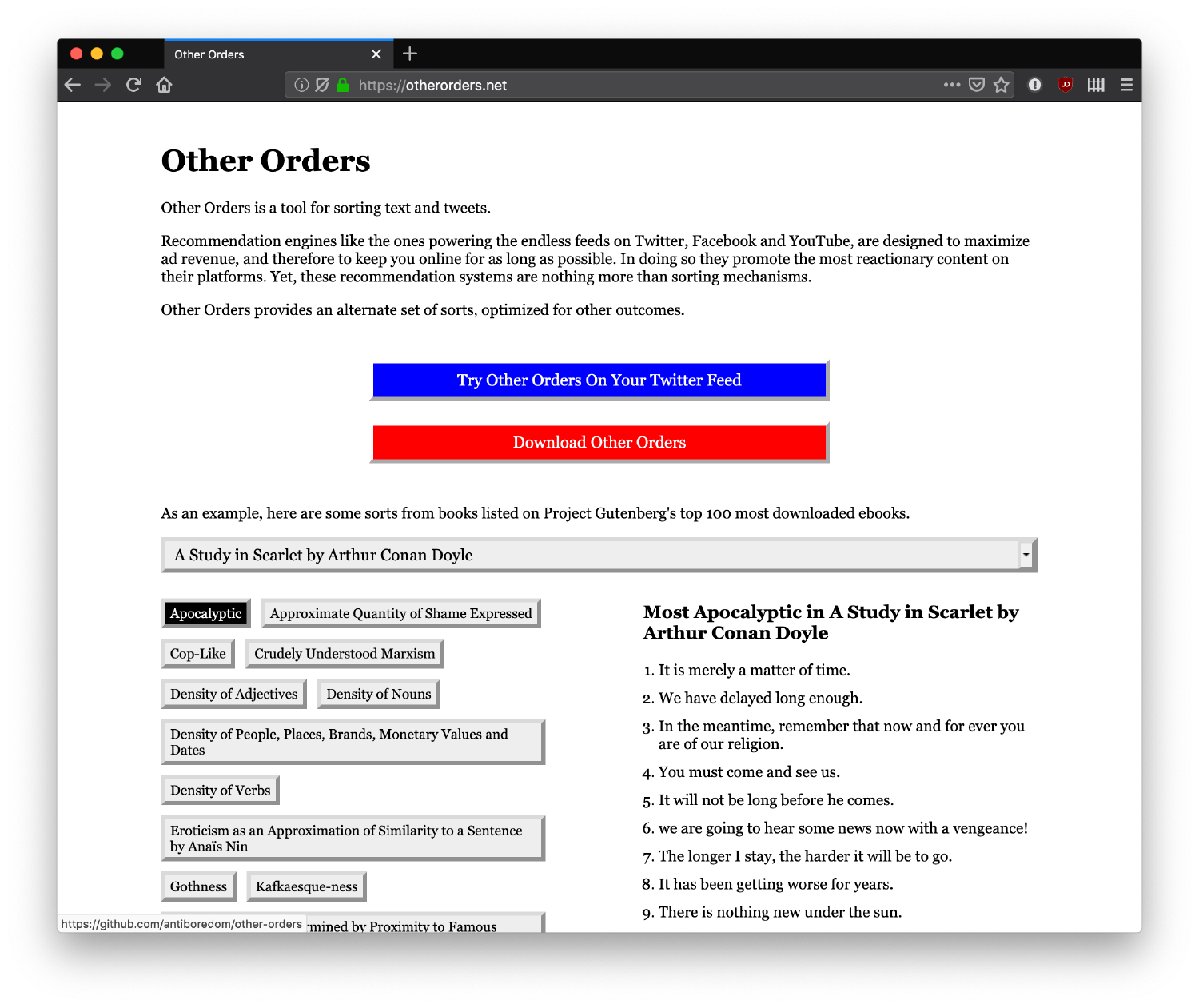
Other Order is a browser-based artwork by Sam Lavigne that reflects critically on the AI that we most often encounter (and that is incidentally amongst the least neutral): the social media newsfeed algorithms that filter, sort, moderate, organize and decide what kind of information we consume on a daily basis. When talking about the idea behind his work, Lavigne writes:
“Recommendation engines like the ones powering the endless feeds on Twitter, Facebook and YouTube, are designed to maximize ad revenue, and therefore to keep you online for as long as possible. In doing so they promote the most reactionary content on their platforms”.
Other Order, instead, presents users with an alternative set of sorting criteria, optimized for other outcomes. You can apply these to your Twitter feed or any other text-based medium. These new sorting criteria facetiously include:
- Apocalyptic
- Approximate Quantity of Shame Expressed
- Crudely Understood Marxism
- Density of Nouns
- Eroticism as an Approximation of Similarity to a Sentence by Anaïs Nin
- Similarity to Values Expressed in TED Talks
- Total Hashtags
This project finds an entertainingly interactive way of showing that AI systems cannot intuit the “best content” to show you using its “innate intelligence”. Instead, the content it serves up is the output of algorithms designed to achieve different sorts of outcomes. The “intelligent” decisions made are proxies of parameters set by Facebook, Twitter, Google, Amazon, and other proprietary platforms. For example, the leaked #FacebookPapers revealed how Facebook crafts its advanced ranking system to keep users hooked, sometimes at the cost of exposing them to hateful content or misinformation. To think that AI-powered systems are elevated above human concerns, greed, politics, interests, ideologies, and biases by virtue of its computational intelligence is to forget that it was created to nudge users and promote the (oftentimes commercial) desires and designs of corporations, government, institutions, organizations, or individual (see also: Error 065).
Error 706: YouTube Mistakes Combat Robots as Animal Cruelty?!
Next in our carrier bag of errors, we present the curious case of YouTube Mistakes Combat Robots as Animal Cruelty?! Not Impressed. This video by Youtuber Maker’s Muse details how people in the robot combat community got multiple videos removed from Youtube because the automated moderation algorithm thought two remote-control machines fighting constitutes animal cruelty. The humour is easy to find in this case, seemingly suggesting that the AI-powered content moderation system was distressed about perceived “machine cruelty”.
Image recognition or machine vision systems are probably some of the most prevalent practical applications of AI technology in everyday software (think: Google search, Facebook, iPhones, digital photography, Tiktok, Instagram, airport security, surveillance systems). But while these systems easily impress us with their uncanny ability to intelligently identify images without our perceptible assistance, when presented with abstractions, edge cases, or ambiguity they betray their underlying stupidity.
The case of mistaken machine/animal cruelty is also part of a wider collection of related items from the ALC blog (see Error 413). You can click on them to read the articles:
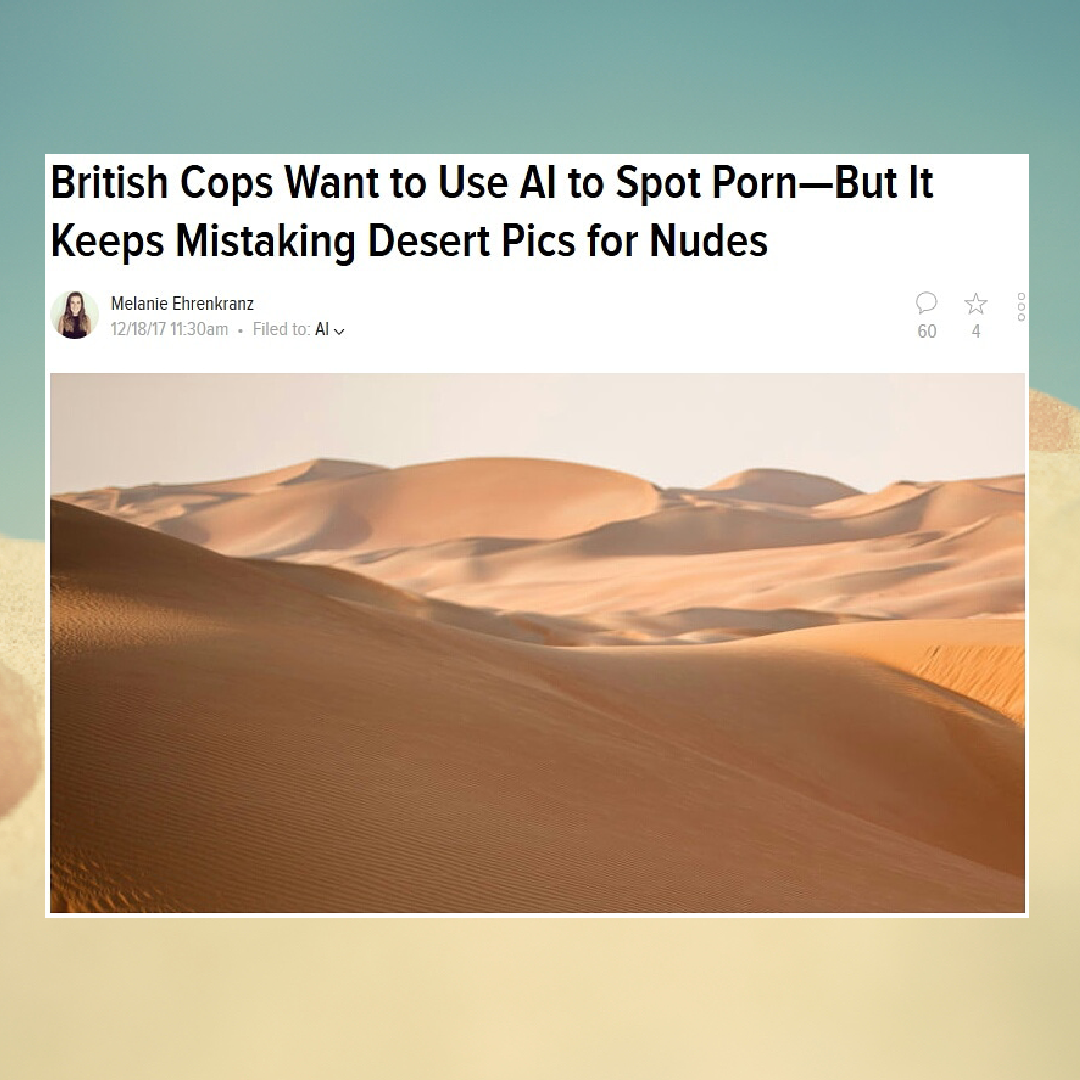

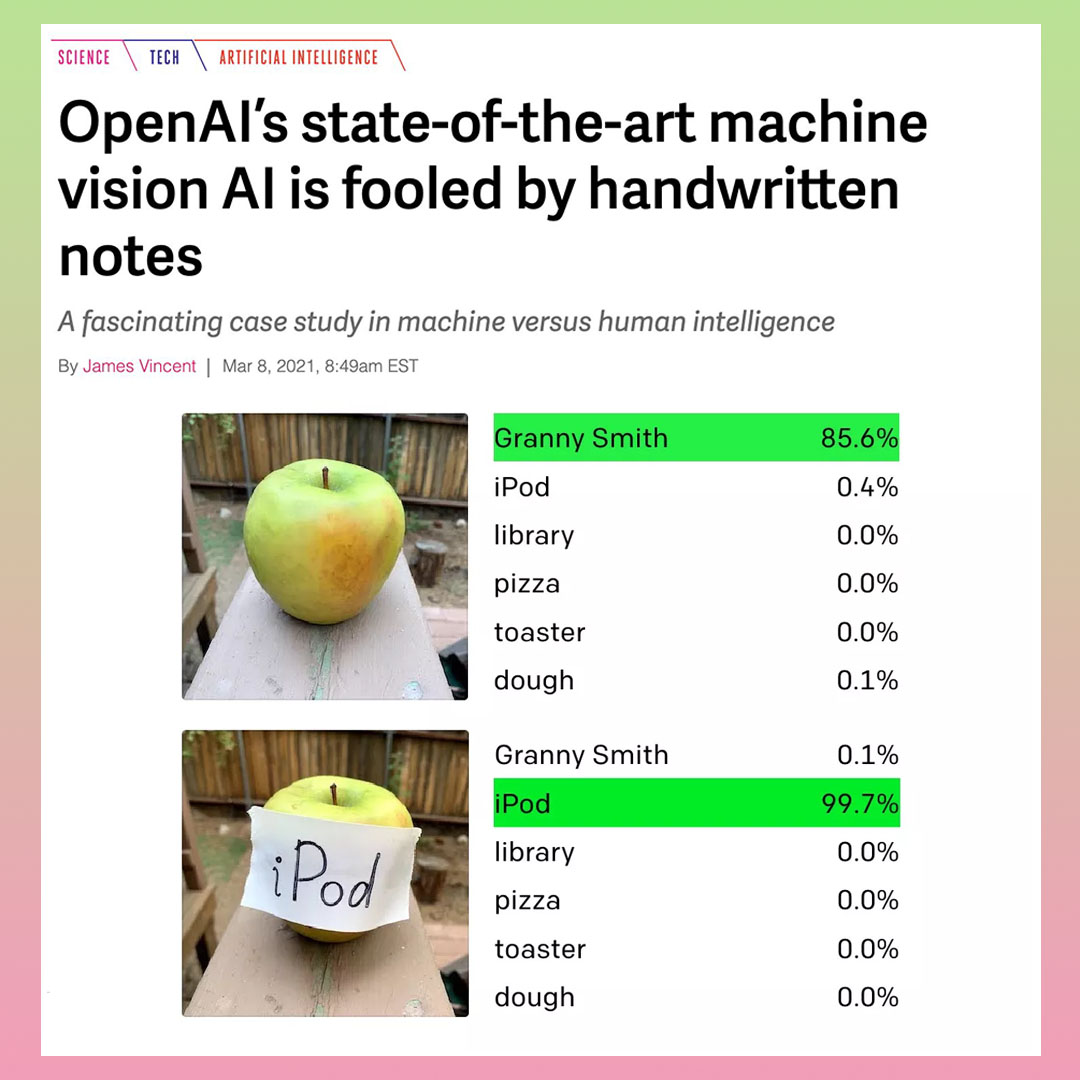
While all of these cases are funny. At the same time, it points towards a deeper fundamental problem with AI’s inability to make more nuanced and intelligent judgments and decisions. As Azar, Impett and Cox write in Ways of Machine Vision, and introduction to the open A Peer-Reviewed Journal About Machine Research:
"What are the political consequences of automated systems that use labels to classify humans, including by race, gender, emotions, ability, sexuality, and personality? Computer vision systems make judgements, and decisions, and as such exercise power to shape the world in their own images, which, in turn, is built upon flattening generalities."
The same inability of AI systems to make intelligent, instead of mere automated, judgments has led to the profoundly troubling instances of Google Image recognition labelling black people as primates. Or as in the case of Facebook, its automated moderation allowed the live-streaming of mass shootings by perpetrators because the AI labelled it as paintball games or a trip through a carwash.
Error 988: ImageNet Roulette
As AI technologies permeate every instance of our social and intimate lives, it becomes crucial to question their inner workings. Another angle to examine AI is through looking at the datasets on which they are trained. AI’s so-called ‘intelligence’ is a direct outcome of the data it is trained on, and specifically how that data was “labelled”.
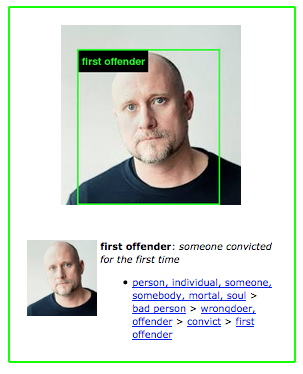
One of our favourite artists working in AI is Trevor Plangen, who collaborated with renowned AI scholar Kate Crawford on a project titled: ImageNet Roulette. This artwork exposed the popular AI training database ImageNet to public scrutiny through an interactive installation that was part of Plangen and Crawford’s exhibition titled Training Humans.
ImageNet Roulette openly explores what occurs behind the scenes of AI training and how training databases can result in biased AI systems (see also: Error 706) . The artwork was trained on the ImageNet database, a colossal collection of labelled images that has been extensively deployed in the training of AI systems worldwide. Composed of images gathered from the internet, this database has been labelled by humans to allow software developers to train their AI algorithms on different categories such as objects, nature, people, etc.
Through an interactive web-based app that was available for a limited time, anyone could explore ImageNet's person category by uploading a selfie or any picture with people on it. The ImageNet Roulette system would then label the image with tags such as: "man", "woman", “individual”, “economist”, etc. However, when confronted with a darker-skinned person it would often use terms such as “Jihadist”, or “adulterer” when labelling an image of a woman.
The project had an element of entertainment to it, and participants shared the nonsensical and absurd labels placed on their photos via social media. Yet by showing just how racist, misogynistic, and discriminatory these ImageNet categorizations can be, ImageNet Roulette also posed the question: if this same database is used for other less transparent purposes (for example screening passengers at airports), what would be the social consequences? It is algorithmic stupidity at its crudest and cruellest. As the duo wrote on the project website:
“It lets the training set ‘speak for itself,’ and in doing so, highlights why classifying people in this way is unscientific at best, and deeply harmful at worst.”
AI systems need training, and compiling the massive amounts of data required to train these systems is a resource-intensive undertaking often overcome by relying on open databases like ImageNet. Yet these datasets are embedded with the worldview, biases, and prejudices of the people who selected, labelled, and categorized the data (see also: Error 432). To dream beyond AI, we should also start dreaming of better, more inclusive, more diverse databases. We need to realize that any system has a worldview and cannot be neutral. Yet, this same realization can encourage us to involve as many worldviews, perspectives, people, and cultural viewpoints as possible. If we can’t create neutral, error-free, technologies - then at least we can strive towards more transparent, accountable and more inclusive ones. To dream beyond AI is to dream of the technological pluriverse.